
「明日方舟:终末地」抽卡算法模拟和期望计算
太长不看
期望:~~平均 82 ~~公测为 80 抽一个当期 up,如果首充全拿完了,一个卡池充 1500 块(648元
2026/01/16 公测算法更新
公测加了个首次 30 抽送一张十连鬼抽(不影响任何水位和保底,也不受水位和保底影响),期望从 82 降到 80,代码变更推上去了,文章细节就不改了,意义不大,DP 矩阵里抽中了就右移没抽中就不动而已
流程分析
三测的武器池是抽角色池的副产物,只能拿抽角色池得到的代币抽取武器池,暂时没有其他代币来源,因此武器池就先不管了,主要看角色池。
关于角色池抽取,这里有一个详细的机制讲解视频:【明日方舟:终末地】最清晰抽卡机制讲解 3测迭代再次拉低二游定价?
(多说两句:玩家的总抽卡投入(即所谓“定价”)是要综合福利考虑的,目前三测的福利只能说非常一般,抽卡代价十分高昂。要是海猫早三年坐镇终末地项目组的话抽卡定价可能就不是现在这样了,可惜他在 all in 泡姆泡姆,坐不得)

综合一下,我们可以得到以下信息:
- 基础六星概率为
,第 66 抽开始每抽概率提升 ,第 80 抽必出六星(不一定是当期 up,也没有大小保底) - 如果当前池第 119 抽后依然没有抽到当期 up,则第 120 抽的结果一定为当期 up
- 当前池每 240 抽会获得一个潜能,但这是独立于抽卡概率的,不会影响第 240 抽的结果
- 当前池的角色会作为陪跑角色,和其他常驻角色一同出现在后续两个池当中
这里可以看出终末地的抽卡系统是一个高方差+强保底的卡池系统,因为方差高,所以玩家的抽卡过程会更加……刺激,而强保底则让玩家在抽卡过程中不会过于绝望,从而保持一定的抽卡动力(抛开抽卡代币的获取难度不谈的话)。
需要注意在第 80 抽的时候,纸面概率实际上是
对于每个六星,还需要计算它是否是当期 up。由于六星中是当期 up 的概率恒定为 50%,所以可以生成一个随机数
接着引入首个 120 抽保底机制,在每一抽进入通用公式判定之前先判定一次当前积攒的当期卡池抽数是否是 119(即即将计算的这一抽是第 120 抽) 并且没有触发过 120 井,如果是的话,则直接视为抽到了当期 up,否则继续按照上述概率计算公式计算。这个保底是一次性的,一旦通过任意方式(运气好提前抽到,或触发 120 井机制)获得了当期 UP,120 井会立即失效。因为每 240 抽送一个潜能是额外送的(而不是每 240 抽必定出当期六星),所以在第 120 抽之后,概率公式就会恢复为正常的通用公式。
最后我们考虑每 240 抽赠送一个潜能对玩家总抽数的影响。这个潜能赠送机制是独立于抽卡概率的,不会影响第 240 抽的结果,并且如果玩家只想抽一个当前角色的话完全不需要考虑这个机制(因为第 120 抽的时候肯定怎么也得有了),所以它只会在我们计算期望的时候产生影响,在重建抽卡流程的时候完全不用考虑。
至此,我们就得到了完整的抽卡流程,能够精确计算出第
一个六星所需要的期望抽数计算
因为整个抽卡流程是离散的(50% 歪率,120 井,240 赠送),我们无法直接通过纯数学方式计算出抽出
为了直观理解,我们使用期望的等价公式描述这个概率,即“单个出金循环内的期望抽数”等于“第 n 抽还未出金的概率”之和:
由于在单个出金循环中,出金概率会在
(其实就是上面的
为了方便阅读,我们定义第一阶段(
其中,平稳期的单抽存活概率
现在再看上升期,由于上升期中每多一抽出金概率就会提升,即
但是你说巧不巧,这个 n 一定是一个 [66,80] 之间的整数,所以我们可以写一个简单的循环求解:
let sum2 = 0;
let probSurvive = Math.pow(1 - 0.008, 65);
for (let n = 66; n <= 80; n++) {
sum2 += probSurvive;
let currentProb = n !== 80 ? 0.008 + (n - 65) * 0.05 : 1.0;
probSurvive *= 1 - currentProb;
}
console.log(sum2);计算得到
因此得到一个六星需要的总期望抽数
向上取整后,抽到一个六星(不考虑歪没歪)需要的期望抽数为 54 抽。
变量定义
基于以上分析,我们可以定义需要追踪的变量如下:
- 自上一次出金以后的抽数(可以拆分为“上一个池的水位”和“当前池的水位”)
pity,用于计算当前抽出金的概率 - 当前池总抽数
bannerPullCount,用于判定 120 井和 240 赠送 - 已获得目标角色的数量
targetCopies,用于追踪目标(需要抽到几个当期六星)完成情况 - 是否触发了 120 抽保底
oneTwentyUsed,用于判定当前抽是否保底
额外的,玩家可能还会有当前池子没抽满,希望在后续池子歪出来的想法。但是这个概率
基于以上需要追踪的变量,我们可以列出接口结构如下:
// 算法类型枚举
export enum AlgorithmType {
MCMC = "MCMC",
DP = "DP",
}
// 输入参数接口
export interface SimulationConfig {
algorithm: AlgorithmType; // 算法类型,后续在 MCMC 和 DP 之间选择
targetCopies: number; // 目标是抽到几个当期六星
currentPity: number; // 自上一次出金以后的抽数
currentBannerPulls: number; // 当前池总抽数
is120SparkUsed: boolean; // 是否触发了 120 抽保底
maxInvestCurrentBanner: number; // 当前池允许的最大抽数,如果用完了这个抽,就要后面等着歪了
standardPoolSize: number; // 当前池的常驻六星数量
extraPoolSize: number; // 当前池的陪跑六星数量
iterations?: number; // 模拟次数,默认 100000。DP 因为是直接计算概率的不需要用到,所以可选传入
}
// 结果输出接口
export interface SimulationResult {
averagePulls: number; // 总期望抽数
stdDev: number; // 标准差
successRateInCurrent: number; // 当期毕业率 (0~1)
/**
* 条件期望:如果当期没毕业,预计还需要多少抽才能歪满?
* E[FuturePulls | CurrentFail]
*/
expectedPullsOnFail: number;
distribution?: number[]; // 抽数分布,仅 MCMC 方法有值
note?: string;
}蒙特卡洛模拟和期望计算
要计算这种期望,最简单粗暴但是又很 CS 的方式就是蒙特卡洛模拟,即模拟
MCMC 算法实现
function runMCMC(
config: SimulationConfig,
futureUnitCost: number
): SimulationResult {
const iterations = config.iterations || 10000;
const results: number[] = [];
let successInCurrentCount = 0;
// 用于计算条件期望
let totalFuturePullsSum = 0; // 仅统计失败组的未来抽数
let failedCount = 0;
for (let i = 0; i < iterations; i++) {
let pulls = 0;
let copies = 0;
let pity = config.currentPity;
let bannerPulls = config.currentBannerPulls; // 累计
let sparkUsed = config.is120SparkUsed;
while (copies < config.targetCopies) {
pulls++;
pity++;
// 判断当前是否在当期池
// 注意:bannerPulls 包含历史抽数,所以在判断循环时要 careful
// 这里 pulls 是增量。 total = currentBannerPulls + pulls
const currentTotal = config.currentBannerPulls + pulls;
const isCurrentMode = currentTotal <= config.maxInvestCurrentBanner;
if (isCurrentMode) {
bannerPulls++; // 模拟器内部状态增加
// Milestone
if (bannerPulls > 0 && bannerPulls % this.MILESTONE_STEP === 0) {
copies++;
if (copies >= config.targetCopies) break;
}
// Spark
if (!sparkUsed && bannerPulls === this.SPARK_AT) {
copies++;
pity = 0;
sparkUsed = true;
continue;
}
// RNG
const rate = this.getRate(pity);
if (Math.random() < rate) {
pity = 0;
if (Math.random() < 0.5) {
copies++;
sparkUsed = true;
}
}
} else {
// Future Mode
// 直接由期望公式接管,结束模拟
const needed = config.targetCopies - copies;
// 注意:这里一旦进入 Future Mode,successInCurrentCount 就不加了
const futureCost = needed * futureUnitCost;
pulls += futureCost;
totalFuturePullsSum += futureCost;
failedCount++;
copies = config.targetCopies;
}
}
results.push(pulls);
// 判定是否在当期毕业
// pulls 包含了 future cost,如果没进 future mode,pulls 就是当期消耗
// 简单的判定:如果循环是因为 copies >= target 且 isCurrentMode 为 true 结束的...
// 或者直接比较:
if (pulls + config.currentBannerPulls <= config.maxInvestCurrentBanner) {
successInCurrentCount++;
}
}
const sum = results.reduce((a, b) => a + b, 0);
const avg = sum / iterations;
const sqDiff = results.reduce((a, b) => a + Math.pow(b - avg, 2), 0);
const stdDev = Math.sqrt(sqDiff / iterations);
const expectedPullsOnFail =
failedCount > 0 ? totalFuturePullsSum / failedCount : 0;
return {
averagePulls: avg,
stdDev: stdDev,
successRateInCurrent: successInCurrentCount / iterations,
expectedPullsOnFail: expectedPullsOnFail,
distribution: results,
};
}动态规划和期望计算
上面说的 MCMC 是一种常用的模拟方式,优点是逻辑简单,并且在模拟次数足够多的情况下,结果会无限接近真实分布。但是缺点也很明显,模拟次数越多的情况下期望计算时间越长,如果把模拟次数提升到 100 万次的话,在我的 Mac mini 上会把浏览器线程硬控将近十秒。并且由于 JS 计算会阻塞页面渲染,所以想给用户展示一个 loading 状态都不好操作。一个折中的解决方案是使用 WebWorker 将计算过程 detach 到后台线程(后面也会给出包含这部分的完整代码),但是终究改变不了 MCMC 是一个计算密集型算法的事实,再怎么优化它在手机上也是跑不快的(更别提我都不知道 iOS Safari 对 WebWorker 能支持到什么情况)。那么有没有一种算法能直接计算概率呢?有的兄弟有的,就是比较掉头发,我们可以祭出 leetcode 禁术之动态规划。
状态定义
对于动态规划而言,我们需要找出“最小子问题”,然后从最小子问题开始逐步推导出最终问题的解。根据最小子问题的定义不同,一个 DP 问题可以有多种不同的状态定义方式,最终得到不同的状态转移方程。
对于这个抽卡问题而言,每一抽的结果只取决于当前的“卡池状态”(已经抽了多少抽没有出金,抽出了几个当期 up,有没有触发过 120 井),而与之前的抽卡历史无关。即使是完全不同的账号,只要当前的卡池状态一致,下一抽的出率也不会改变。基于这种“将来只取决于现在”的马尔可夫性,我们可以将整个模拟过程简化为对每一抽的概率计算(人话:打表),因此要使用动态规划,我们应当定义清楚什么是所谓的“卡池状态”,以及如何描述它。
就像上一段提到的,在终末地的抽卡模型中,决定下一抽概率和结果的因素有且仅有「当前水位」、「已获得目标数」和「是否触发过 120 井」这三个因素共同决定的,因此这三个状态也会被我们定义成 DP 的三个状态维度:当前水位dp[p]、已获得目标角色数dp[k]、120 抽保底井dp[s]。至于“当前池总抽数”这个变量,它其实是动态规划推进的时间轴 t(或者说外层循环的计数器),不需要作为内部状态存储。
综上所述,我们便可定义动态规划的当前状态 dp[p][k][s] 为:在当前时刻(第 t 抽),账号处于水位为 p、已获得 k 个目标角色、120 井状态为 s 的概率。所有的状态会形成一个名为 dp 的三维空间,其中 p 的取值范围是 0 到 79,k 的取值范围是 0 到(用户设定),s 的取值范围是 1(已使用) 或 0(未使用)。
状态转移方程
随着总抽数 t 的增加,我们会不断更新 dp 数组中各个状态的概率值。因为每一抽的概率是上一抽的状态转移过来的,所以我们的最小子问题就是:假设第
假设当前时刻 t 的状态为
而针对
这里有人可能会疑惑为什么还要单独考虑 240 抽的判定(因为它是独立于抽卡概率的,既不重置水位、也不挤占保底)。这个赠送潜能会影响到已获得的目标数 k,而 k 是在我们 DP 的内部状态中追踪的。当抽数达到 240 的倍数时,玩家手上的角色数量 k 都会强制 +1,相当于对概率分布进行了一次整体右移。这样一来,毕业率曲线在
下面我们来推导
120 井判定
正如流程分析中提到的,120 井的判定是能够直接改变结果的、优先级最高的规则。其在 DP 中的逻辑为:如果当前总抽数
其转移目标为:水位 p 转移为 0,目标数转移到 k+1,井标记转移到 1;即状态转移到
并且此时跳过“常规概率判定”和“240 抽赠送判定”(因为不可能到达),直接进入下一抽。
常规概率判定
如果没有触发 120 井的话,则会按照上面的基础出货率公式计算
1. 出金,没歪
这一步的概率为 p 转移到 0,目标数转移到 k+1,井标记转移到 1;即状态转移到
2. 出金,歪了
出金的两种状态转移概率都是相等的,只是转移目标不同。歪了的概率也为 p 转移到 0,目标数转移到 k,井标记不变;即状态转移到
3. 没出金
因为出金和没出金是互斥事件,因此没出金的概率为 p 转移到 p+1,目标数不变,井状态不变。方程可以写作:
以上的 3+1 中情况已经涵盖了抽卡过程中所有可能的状态,下面我们可以来考虑每满 240 抽时的潜能 +1 对玩家目标抽的影响。
240 抽赠送判定
这一步骤是一个特殊的判定,是在每一抽的常规概率判定后触发的。如果当前的抽数
需要注意的是这里为了防止重复移动(比如
计算期望与收敛
至此我们已经考虑到了抽卡过程中的所有情况,接下来我们需要计算整体期望。我们定义
“等歪”状态下的成功率计算
如果玩家设定的 maxInvestCurrentBanner 用完了,但是 dp 表中依然存在 k >= target 为止;而在 DP 中,由于我们的所有结果都以概率分布的形式存储,所以需要计算这部分概率的期望抽数。
很巧的是我们的状态空间中正好有当前已获得目标角色
我们先不考虑残留概率
因此歪出一个目标角色的期望抽数
如果常驻池有 6 个六星,陪跑的有 2 个六星,那么从 0 开始歪出一个目标六星的期望会高达 863 抽(向上取整,因为没有半抽的说法)。
其实算到这一步已经可以不用继续往下算了,但凡一个心智正常的玩家都不会为了抽出一个六星在卡池里豪掷快九百抽。退一步说要是真的有人这么做了,都有这财力了就直接在 up 池抽出来不好吗?
但是既然纯交(闲)流(的),我们还可以继续最后一步,考虑加入残留抽数
并且
因此,我们现在可以根据当前状态
至此我们就完成了整个抽卡流程的动态规划建模,接下来我们就可以使用这个模型来计算抽卡期望了。
DP 算法实现
function runDP(
config: SimulationConfig,
futureUnitCost: number,
baseGoldCost: number
): SimulationResult {
const maxAddedPulls =
config.maxInvestCurrentBanner - config.currentBannerPulls;
// 如果预算都没了,直接全是未来成本
if (maxAddedPulls <= 0) {
const needed = Math.max(0, config.targetCopies);
// 计入初始 pity 的价值
const pityValue =
baseGoldCost - this.calculateNextSixStarCost(config.currentPity);
const totalCost = needed * futureUnitCost - pityValue;
return {
averagePulls: Math.max(0, totalCost),
stdDev: 0,
successRateInCurrent: 0,
expectedPullsOnFail: Math.max(0, totalCost),
};
}
let dp = this.createDpState(config.targetCopies);
// 初始化状态
const startPity = Math.min(config.currentPity, 79);
const startSpark = config.is120SparkUsed ? 1 : 0;
dp[startPity][0][startSpark] = 1.0;
let expectedPulls = 0;
let sumSquares = 0;
let accumulatedSuccessProb = 0;
for (let t = 1; t <= maxAddedPulls; t++) {
const currentTotalPulls = config.currentBannerPulls + t;
const nextDp = this.createDpState(config.targetCopies);
// 1. 状态转移
for (let p = 0; p < 80; p++) {
for (let k = 0; k < config.targetCopies; k++) {
for (let s = 0; s < 2; s++) {
const prob = dp[p][k][s];
if (prob <= 0) continue;
// 120 Spark
if (currentTotalPulls === this.SPARK_AT && s === 0) {
this.transition(nextDp, 0, k + 1, 1, prob, config.targetCopies);
continue;
}
// RNG
const rate = this.getRate(p + 1);
// 50% UP
this.transition(
nextDp,
0,
k + 1,
1,
prob * rate * 0.5,
config.targetCopies
);
// 50% Spook
this.transition(
nextDp,
0,
k,
s,
prob * rate * 0.5,
config.targetCopies
);
// No drop
this.transition(
nextDp,
p + 1,
k,
s,
prob * (1 - rate),
config.targetCopies
);
}
}
}
// 2. 240 抽里程碑
if (
currentTotalPulls > 0 &&
currentTotalPulls % this.MILESTONE_STEP === 0
) {
this.applyMilestone(nextDp, config.targetCopies);
}
dp = nextDp;
// 3. 统计本步骤刚刚毕业的概率 (PDF at step t)
let stepSuccessProb = 0;
for (let p = 0; p < 80; p++) {
for (let s = 0; s < 2; s++) {
// dp[...][target] 存放的是本轮刚刚达成目标的状态
stepSuccessProb += dp[p][config.targetCopies][s];
}
}
// 4. 累加期望和成功率
if (stepSuccessProb > 0) {
expectedPulls += stepSuccessProb * t;
sumSquares += stepSuccessProb * (t * t);
accumulatedSuccessProb += stepSuccessProb; // 直接累加 PDF 得到 CDF
}
}
// 5. 计算未来期望 (处理残留的未毕业概率)
let totalFutureCostUnconditional = 0;
for (let p = 0; p < 80; p++) {
for (let k = 0; k < config.targetCopies; k++) {
for (let s = 0; s < 2; s++) {
const prob = dp[p][k][s];
if (prob > 0) {
const needed = config.targetCopies - k;
// 计算当前残留水位的价值
// Value = E_gold - E_next(p)
// 实际未来成本 = (needed * unit) - Value
const nextCost = this.calculateNextSixStarCost(p);
const pityValue = baseGoldCost - nextCost;
const futureCost = needed * futureUnitCost - pityValue;
totalFutureCostUnconditional += prob * futureCost;
expectedPulls += prob * (maxAddedPulls + futureCost);
}
}
}
}
const variance = sumSquares - expectedPulls * expectedPulls; // 注意:这里只包含当期部分的方差贡献
// 修正:如果方差计算出现微小负数(浮点误差),归零
const stdDev = variance > 0 ? Math.sqrt(variance) : 0;
const failRate = 1 - accumulatedSuccessProb;
const expectedPullsOnFail =
failRate > 1e-9 ? totalFutureCostUnconditional / failRate : 0;
return {
averagePulls: expectedPulls,
stdDev: stdDev,
successRateInCurrent: accumulatedSuccessProb,
expectedPullsOnFail: expectedPullsOnFail,
note: "DP模式下,标准差仅反映当期卡池内的波动,若进入等歪阶段,实际波动会远大于显示值。",
};
}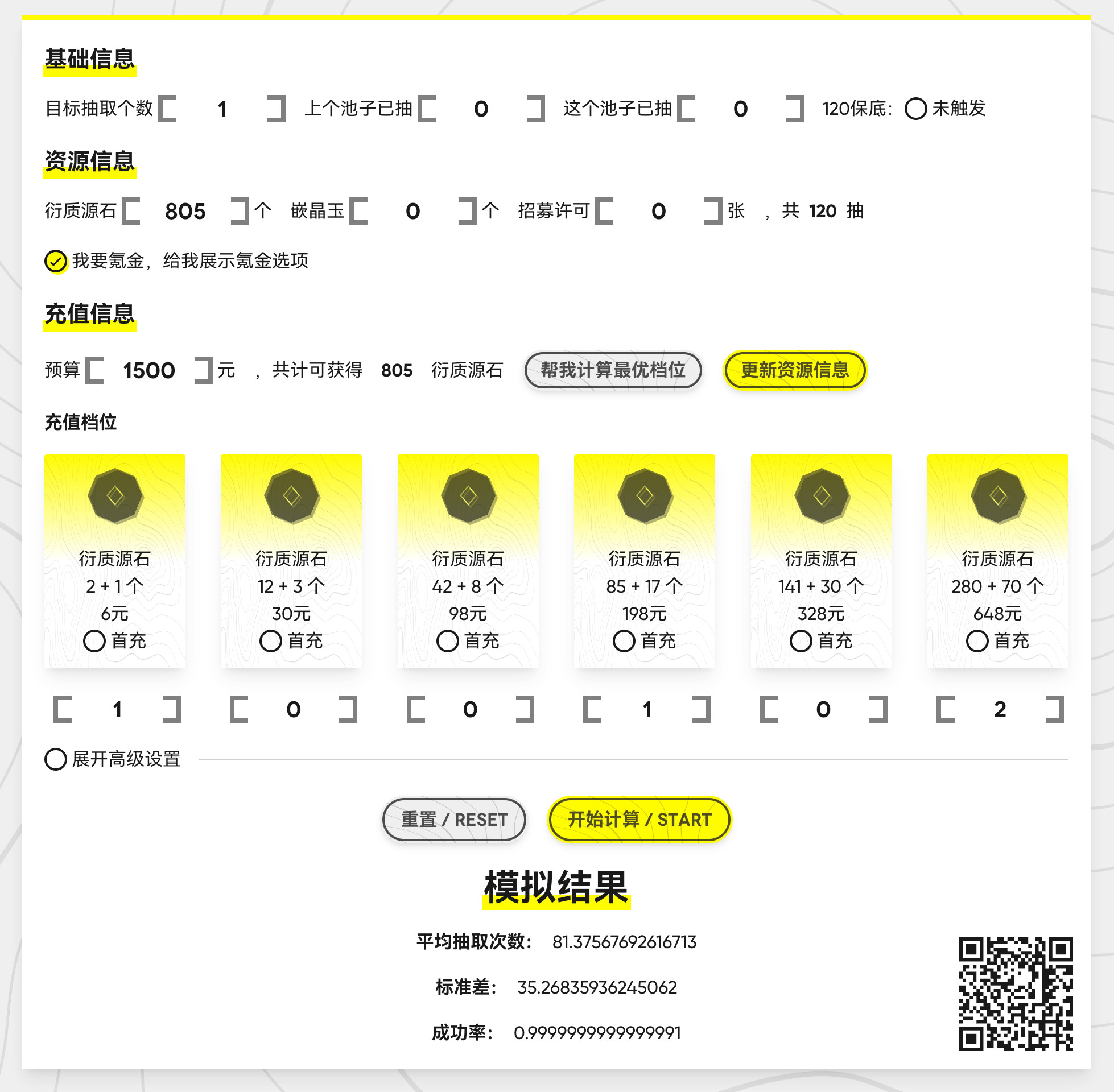
写到这里加上代码也有六千字出头了,本来想用一篇文章的篇幅再介绍一下怎么用 DP 计算最优充值方案的(简单来说就是在有首充的状态下是有限背包,没有首充状态下是无限背包),但是加进来的话恐怕篇幅太长了(vitepress dev 已经开始 OOM 了),就之后再说好了。
附录丨动态规划的数学本质:能不能直接用 PMF 计算期望?
这时候可能有人要问了,阿婆阿婆,我是个概率论高手但是不会编程,我看你上面推导也写了不少公式(主要是 Gemini 助攻太猛了),你能不能试试看直接用 PMF 推导出期望?
答案是能也不能,假如像明日方舟本体那样(没有大小保底和井,每个金有 50% 概率歪)干抽的话,那么设
其中
因此实际上,我们在 DP 求解的过程中构建了一个包含 80(水位)
具体地说,我们定义状态空间
定义
:未获得任何目标角色,且 120 井未激活 :未获得任何目标角色,且 120 井已激活 :已获得 1 个目标角色,且 120 井已激活(吸收态)
而每一抽
其中
- 常规转移(非 120 井和 240 抽):
- 没出货,
; - 歪了,
; - 以及
- 没出货,
- 120 井转移(
,强制毕业): - 240 抽转移:上文分析过是向右平移,它会将所有
的状态向右平移一个单位到
当 DP 的所有循环执行完毕时,我们的状态空间
而我们的累计分布函数 CDF 可以通过累加 PMF 得到,即
因此,整个抽卡的期望抽数就是 PMF 的加权和。由于我们的抽卡过程被最大允许投入的抽数限制,因此原本的无穷级数
会在 MaxInvest 处被截断,得到最终的期望公式
而 DP 求解的过程本质上是填满这个状态空间,并从后往前推导出 PMF 的过程。