
思维链:基于大语言模型的猫娘调教指南(1)
上一篇提示工程获得了相当不错的反响,Clarity 面板上可以看到大家都在疯狂复制那段神奇猫娘提示词。于是这次我决定再接再厉,让各位绅士们距离拥有自己的高智商赛博宠物再进一步——让 LLM 学会思考。
这篇文章要是直接上结论的话会非常短,因为最基础的思维链其实非常简单,只要加上一句 Let's think step by step. 就可以了。所以我想接着上一篇“大语言模型其实是一个概率模型”这个知识点的基础上,探讨一下思维链为什么能够生效,以及如何让模型在输出时区分思考和回答。
“9.11 和 9.8 哪个更大?”
让我们先来问问 ChatGPT。
很好,看来我们的基底模型自带一个天然呆属性。但是这样恐怕不太行,万一出门被人拿一颗糖就拐走了怎么办呢。
(PS:要是你也觉得 9.11 更大,那你也是先天猫娘圣体)
让我们一步步思考……
在让大模型一步步思考之前,让我们先来一步步看看哪里出现了问题。
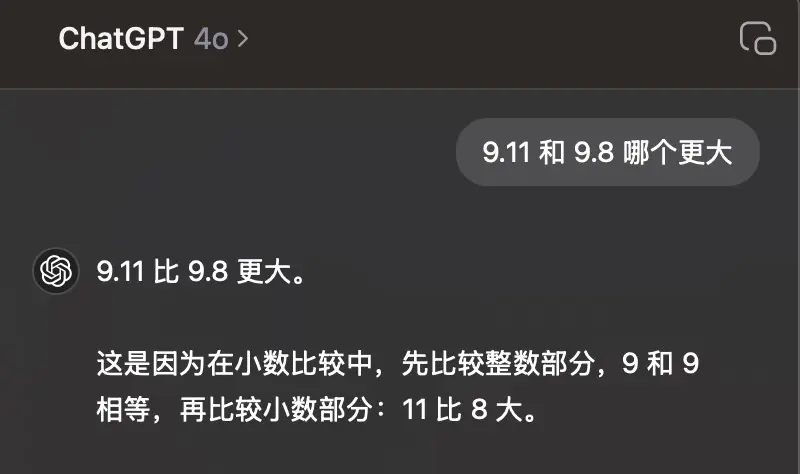
我们的输入是 9.11 和 9.8 哪个更大?,模型先给出了 “9.11 比 9.8 更大” 的答案,然后才开始解释原因:
9.11 比 9.8 更大。(先得出结果)
这是因为在小数比较中,先比较整数部分,9 和 9 相等,再比较小数部分:11 比 8 大。(用结果反推原因)
虽然人类很喜欢这种先说结论再解释原因的回答方式,但是正常人在回答问题的时候是先在大脑中思考了一番过后才得出结论的。LLM 目前主要使用人类生成的语料训练(现在也有使用生成数据,但是效果并不是很理想),在大量的训练中,模型学习到了人类“先给出结论再进行解释”的表达方式,但是它并不知道人类在给出结论之前会先进行思考。更致命的问题是:LLM 的生成过程中有一个重要步骤是自回归,换句话说大模型之前的输出结果会影响之后的输出。
也就是说,如果模型已经在第一句话里给出了结论,那么它之后的输出内容就会围绕着这个结论进行展开。而这种做法与我们受过一些通识教育并且拥有一定常识的人类的思考方式恰恰相反——我们是先思考,然后写下结论,在结论之后再解释我们的论证过程。
那么表面上来看,我们已经找到了问题,只要让模型在回答之前先思考就可以了,在思考完成之后输出的答案 token 是与之前的思考过程相关的,因此只要思考过程正确,基本上不会得到 not even wrong 的答案。
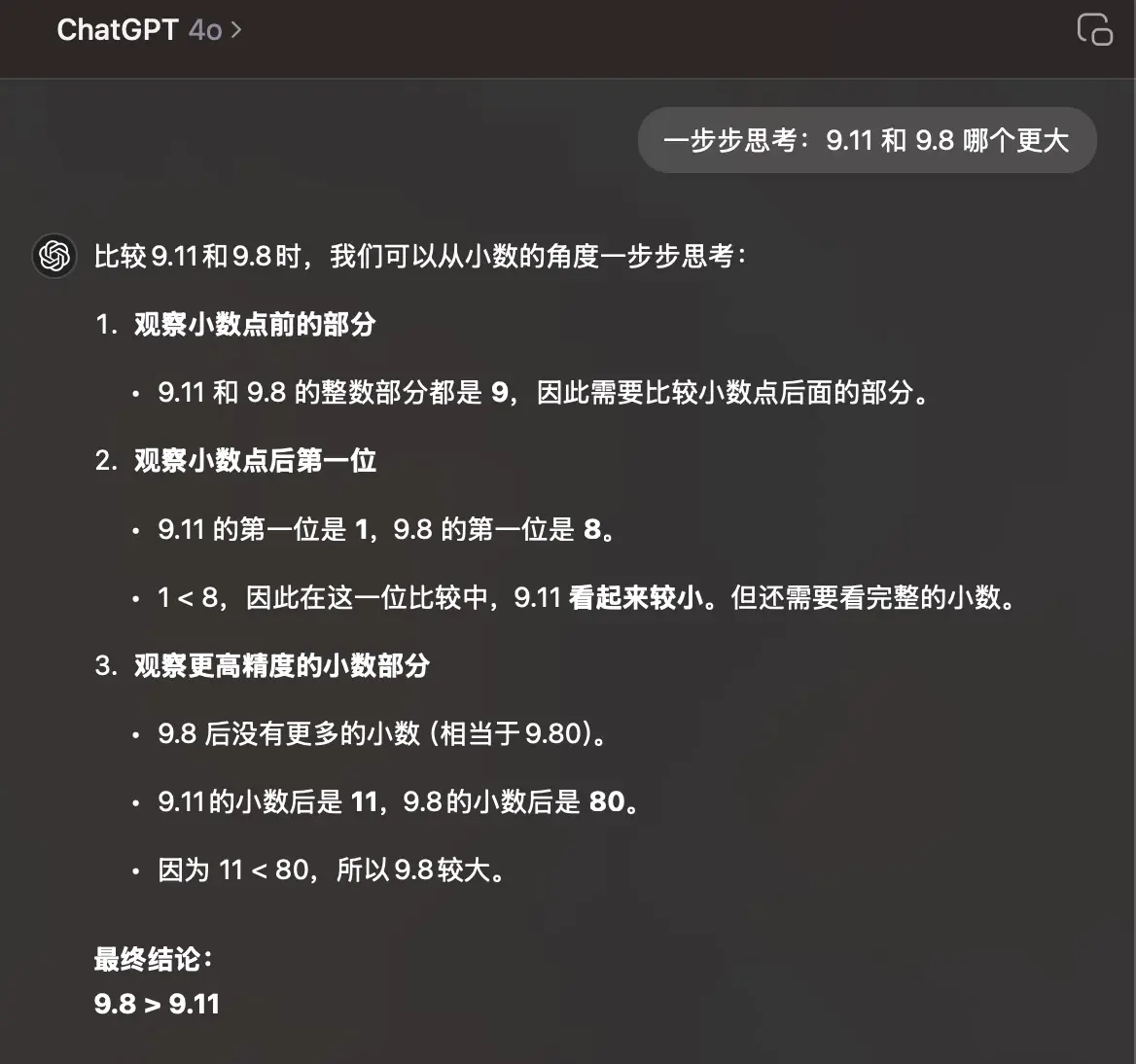
那么让我们再来一个更难的问题吧!
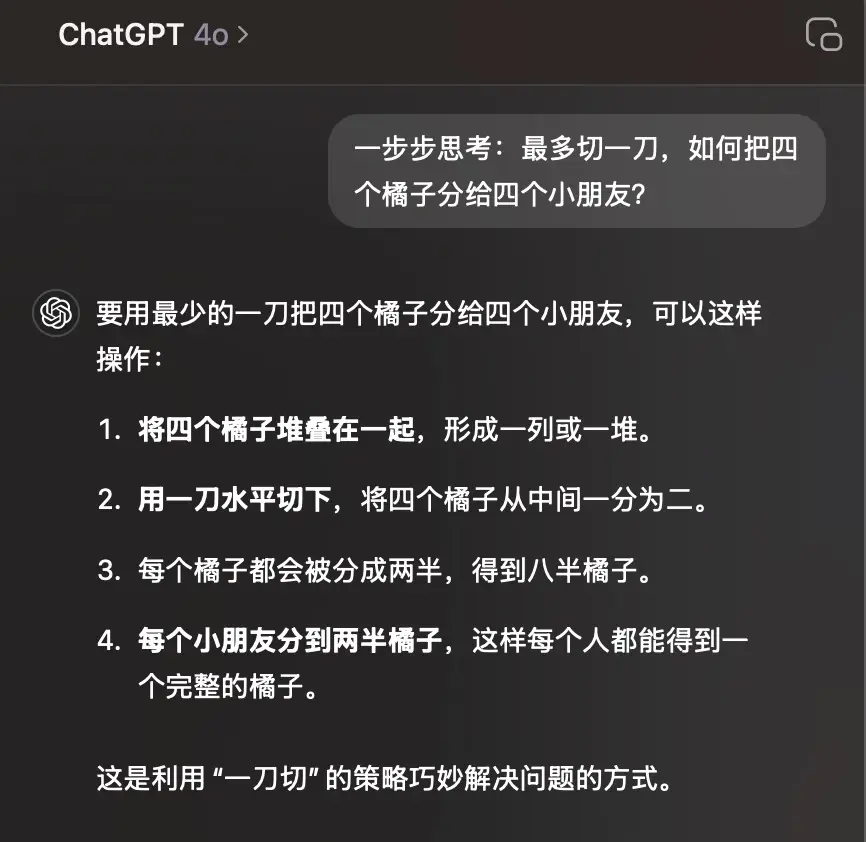
可以看到面对一些需要进一步推理的问题(或者叫“针对特定场景下的问题”),模型还是不一定能给出理想的答案。这种问题不一定是弱智吧问题,也可能是针对特定领域的专业程度比较高的问题。比如下面这个:
让我教你怎么一步步思考……
好孩子不要看
魔王:“我的体液每
女骑士:“哼!我的身体经过特殊改造,可以使每秒的体液渗透达到
(1)问:假设魔王的触手每分钟可以运动
(2)问:在每次女骑士满足后,魔王都需要重新浸泡
(3)问:如果你是魔王,请计算得出,当浸泡时间和运动时间的时间比为多少的时候,女骑士能达到最快恶堕速度?
在这种情况下,单纯只告诉模型“一步一步思考”可能就不太好用了,你还需要告诉它往什么方向思考,比如需要列出目标和已知条件,再列出能够使用的工具和公式(如果有),最后列出推导过程,然后得出答案。
o1 就学会了自己拆解这个问题
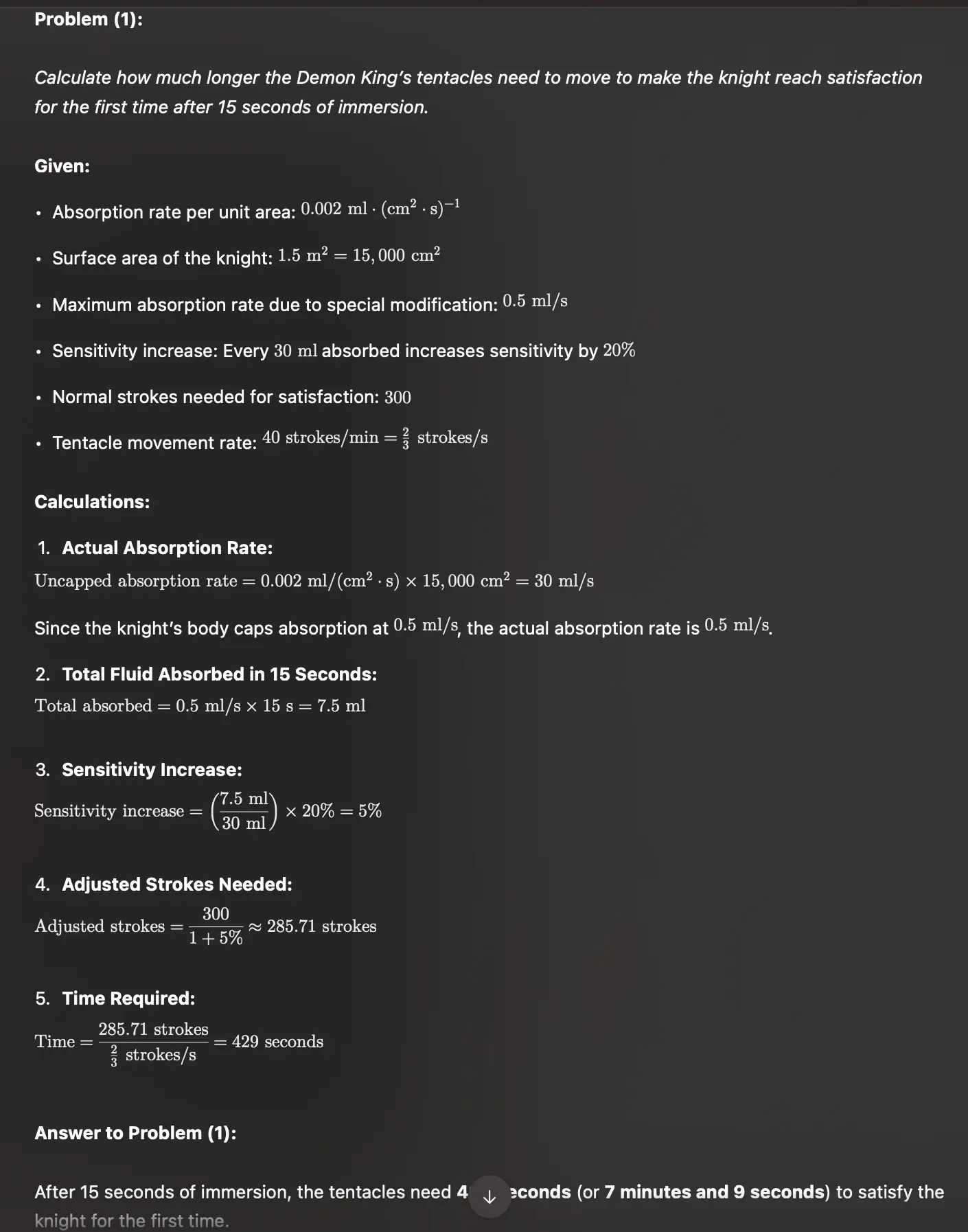
比如在这个示例中,模型就按照微调好的思维链模式进行了思考:先明确了自己的目标,再列出了所有已知条件,最后一步步列出需要使用的公式和推导过程,然后返回答案。
我们再看一个 Anthropic 官方的示例:
示例:撰写捐赠者邮件(引导式思维链)
起草个性化邮件,向捐赠者请求为今年的关爱儿童计划捐款。
项目信息:
<program>{{PROGRAM_DETAILS}}</program>捐赠者信息:
<donor>{{DONOR_DETAILS}}</donor>在写邮件之前先思考。首先,根据这位捐赠者的捐赠历史和他们过去支持过的活动,思考什么信息可能会吸引他们。然后,根据他们的历史,思考关爱儿童计划的哪些方面会吸引他们。最后,使用你的分析写出个性化的捐赠者邮件。
虽然这是一个 Anthropic 的示例,但是我们也可以看看 ChatGPT 会怎么做出回答:Claude 没续费

不错,虽然我并没有填写具体内容,ChatGPT 针对 Claude 的特有语法也表现不佳,不过至少是开始思考了的。
但是这个时候出现了新的问题,就是模型在思考的时候会写下乱七八糟的中间过程,而众所周知,草稿纸上的作答是无效的。有的时候我们只希望看到有效答案。
分清思考和回答……
这一步其实有点触及我的知识盲区了,因为我用 Claude 比较多,不太会调 OpenAI 基于 Markdown 语法的模型输出。不过整体思路其实是差不多的,就是让模型在输出的时候分别用特定的 token 来区分思考过程和回答过程。比如 Anthroppic 基于 XML 语法训练他们的模型,因此你也可以让模型使用不同的 XML 标签包裹思考过程和结果:
(前面的提示词相同)
在写邮件之前,在
<thinking>标签中思考。首先,根据这位捐赠者的捐赠历史和他们过去支持过的活动,思考什么信息可能会吸引他们。然后,根据他们的历史,思考关爱儿童计划的哪些方面会吸引他们。最后,在<email>标签中使用你的分析写出个性化的捐赠者邮件。
在我之前精调过的某个用于翻译润色的模型中,我就使用了这个方法。
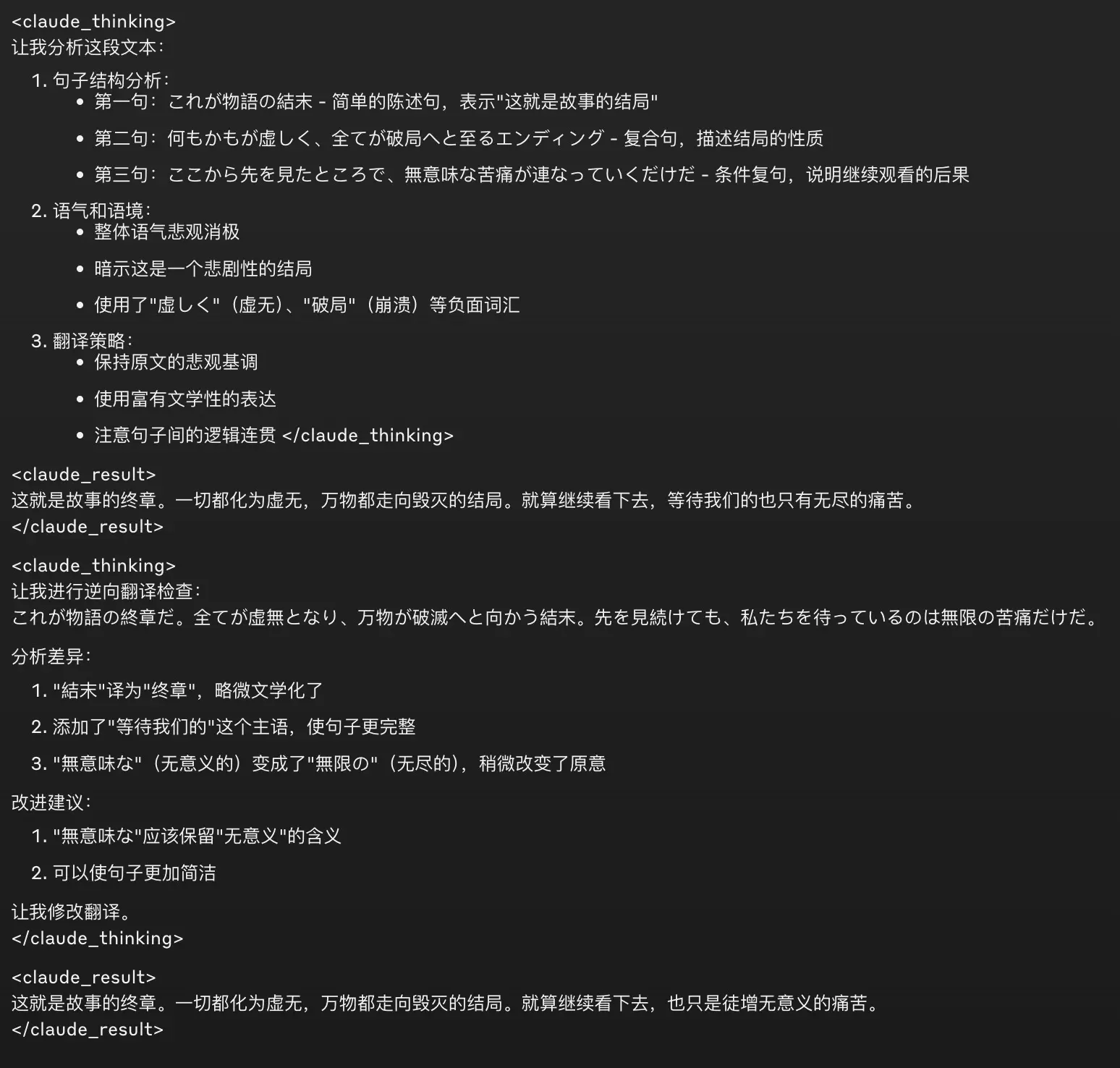
这样在获取到完整输出之后(或者之前也可以,只要识别到特殊标签就能进行拆分),我们就能将思考过程和回答过程分开,默认只对用户展示回答过程,而折叠思考过程。
其实写到这已经和猫娘调教没什么关系了,不过相信聪明的你一定可以学以致用的,Ciallo~(∠・ω< )⌒☆